Herkese Merhaba;
Uzun bir zamandır burada paylaşımda bulunmadığımın farkettim. Bu nedenle geniş ve kapsamlı bir makale oluşturmaya karar verdim. Bu makalede RedHat Enterprise Linux 5.8 üzerinde Oracle 11gR2 için aktif-pasif cluster kurulumunun nasıl yapılacağını anlatmaya çalışacağım. Başlamadan önce bazı temel terimlere değinmekte fayda olacağını düşünüyorum. Öncelikle cluster'ın ne olduğuna değinmekle başlayabiliriz. Basit olarak cluster bilişim sistemleri üzerinden verilen servislerin mümkün olduğunca kesintisiz hizmet vermesi için, birden fazla öğenin bir araya getirilmesiyle oluşturulmuş bir çalışma modelidir. Birden fazla yöntemi olan bu yapının en çok kullanılan yöntemleri aktif-pasif ve aktif-aktif'dir.
Aktif-Pasif cluster yönteminde, servis aynı anda yalnızca bir cluster üyesi üzerinde çalışabilir. Bu üyeye aktif üye denir. Diğer üyeler bu servisi veren üyeyi belirli periyotlarla kontrol eder ve gerektiğinde belirlenen aksiyonları alır. Bu üyelere de pasif üye denir. Servis aynı anda yalnızca tek bir sunucu üzerinde çalışacağından paylaşılmış kaynaklara ihtiyaç duyulmayabilir. RHEL Cluster Suit aktif-pasif için bir örnek olabilir.
Aktif-Aktif cluster modelinde ise servis birden fazla üye üzerinde aynı anda çalışır. Bu çalışma belirlenen kurallara göre gerçekleşir. Genelde amaç servis devamlılığıyla beraber yük paylaşımıdır. Servis için ortak kaynaklar kullanılacağından toplam sistem performansı Xn sistemlerin toplam performansından küçük olabilir. Üyelerin herhangi birinde oluşabilecek bir problemde servis üzerinde herhangi bir kesinti yaşanmaz ancak servis kalitesinde değişim yaşanabilir..Oracle Real Application Cluster Aktif-Aktif cluster'a örnek gösterilebilir.
Cluster yapısındaki sunucuların her birine "node" denilir. Node'ların cluster işlemleri için birbiri ile haberleştikleri ve ortamdaki diğer ağlardan yalıtılmış ağlara "cluster network" yada "interconnect" denir. Cluster üzerinde çalışan ve kullanıcıların taleplerini karşılayan programlara da servis denilebilir.
Temel konulardan bahsettikten sonra kendi çalışmamızdan söz edebiliriz. Öncelikle bu çalışma için kendi kurulum yaptığım ortamı anlatmak istiyorum. Bu çalışmayı ESX 4.1 üzerinde kurulmuş olan iki adet RHEL 5.8 sanal sunucu üzerinde gerçekleştirdim. Kurulan bu sunuculara iki adet NIC kartı ekledim. Bu kartlardan bir tanesi servis IP'si için diğeride cluster interconnect'i için kullanıldı. Genelde iki node'lu cluster'lar için bu model kullanılır. İkinci olarak sunucular üzerinde oracle çalışacağı için bazı ortak kaynakları da belirtmemiz gerekiyordu. Bu nedenle oracle kullanımı için her iki sunucununda kullanabileceği disk ataması yaptım. Normalde bu işlem SAN bağlantısı olan fiziksel sunucular üzerinde oldukça kolay yapılabilir. Ancak ESX üzerinde bazı özel konfigürasyon yapmak gerekir. Ortak disk atamasıilk node'a aşağıdaki gibi yapılır. Atama yaparken dikkat edilmesi gereken şey scsi id'sini OS diskinden faklı bir scsi id vermektir. Bu haliyle aşağıdaki şekilde görüldüğü gibi kullanılacak disk için ESX tarafından başka bir scsi device tanımlanması sağlanır. Yeni oluşan scsi device'ın özelliklerinden "Scsi Bus Sharing" Physical'a getirilerek oluşturulan bu diskin ESX üzerindeki başka sunucular tarafından da kullanılabilmesi sağlanır.


İkinci node'a da aynı diski göstermek için add harddisk dedikten sonra ilk "Use existed drive" seçeneği seçilir. Diğer node için yanımlanan disk "Storage" lar üzerinden bulunarak eklenir. Bu disk içinde ilk node için belirtilen aynı scsi id kullanılmalıdır. Oluşan yeni scsi device içinde aynı ayarlar yapıldıktan sonra sunucular üzerinde aşağıdaki komutlar root kullanıcısı ile kullanılarak disklere erişimler başlatılmaıldır.
Bu komutları her iki node'da çalıştırdıktan sonra fdisk -l ile disklerin node üzerindeki durumu kontrol edilir.


Burada sonradan değineceğimiz konular olduğu için ayrıntılara çok yer vermedim. Ancak standart Oracle 11g kurulumu için yaklaşık 4.5-5 Gb lık bir disk alanı ve Quorum içinde minimum10 Mb'lık disk alanına ihtiyacımız olacak. 10MB'lık LUN lar bazı storage'lar için sorun teşkil edeceğinden sizde 1 GB'lık bir alan oluşturuabilirsiniz. Bu alanları yukarıda belirtildiği gibi paylaşımlı olarak yani her iki node'un bu alanlara erişimi olacak şekilde oluşturmalısınız.
Bu işlem tamamlandıktan sonra gelelim RHEL Cluster Suit kurulumuna. Bunun için RHEL paket yöneticisi yum'dan faydalanacağız. Ancak RHEL cd'lerinde Cluster Suit yazılımları standart kütüphaneden farklı bir klasörde yer aldığı için yum repository'sini güncellemeniz gerekecek. Cluster Suit kurulumu için aşağıdaki komutu kullanabilirsiniz.
Bu komuutu yazdıktan sonra yum installation media üzerndeki cluster
paketlerini yükleyecektir. Bu adımı her iki sistem üzerinde de
gerçekleştirmelisiniz.
Kurulum tamamlandıktan sonra biraz RHEL cluster yapısına değinmek istiyorum. RHEL cluster yapısında temel olarak 3 kernel module'ü (configfs, dlm, lock_dlm) ve 5 adet service'den (ccsd, groupd, fenced, dlm_controld, gfs_controld) oluşur. Bu servislerden en önemlisi ccsd'dir. Bu servisler cluster yapısından ve cluster'ın sağlıklı çalışmasından sorumludur. Bunun dışında cluster tarafından verilecek hizmetleri yöneten 1 adet (clurgmgrd), cluster durumunu kontrol etmekte faydalanılan 1 adet (quorumd) servisi de cluser içerisinde kullanılır. Cluster'a iat tüm konfigürasyon aşağıdaki xml formatlı dosya ile yürütülür.

Bütün konfigürasyon işlemleri bu dosya üzerinden yönetilecektir. Şimdi ilk olarak cluster node'larımızı ekleyelim. Bunun için dosyası herhangi bir metin editörü ile açıp aşağıdaki satırları ekleyebiliriz.

Burada iki node'lu bir cluster oluşturuyoruz. Node name olarak cluster interconnect ip'lerini kullanmalıyız (İsterseniz hostname 'de kullanabilirsiniz. Ancak DNS kullanıyorsanız IP üzerinden gitmekte fayda var). Cluster'ın çalışması için interconnect network'u kullanmak zorunlu değil ancak sağlıklı çalışması için gereklidir. Cluster node'ları birbirleri arasındaki token'ları bu interconnect üzerinden göndererek diğer sunucuların çalışıp çalışmadığını kontrol edebilirler. Bu haberleşmede oluşabilecek herhangi bir sorun tüm cluster node'larının işlevsiz kalmasına yol açabilir. Best practice'lerde eğer mümkünse bu bağlantıların diğer ağ bağlantılarında yalıtılmış ortamlar üzerinden gerçekleşririlmesi gerektiği belirtilir. Eğer iki node'lu bir cluster kullanacaksanız bu bağlantı için back to back veya cross kablo ile bağlantı da önerilmez. Bunun nedeni cross kablo ile birbirine bağlı iki node'dan bir tanesi kapatıldığında diğer node kendi bağlantısınında "unplugged" olduğunu zanneder ve cluster yapsını kaybettiğini düşünerek servisleri kapatabilir. Eğer bağlantı switch üzerinden sağlanırsa bir node kapatılsa bile diğer node switch üzerinden kendi network'unun ayakta olduğunu anlayabilir. Bu bağlantının önerilmemesi için başka bir neden daha var ancak bu konuya makalenin ilerleyen safhalarında değineceğiz.
Node name'lerle beraber cluster internal işlemleri için her node'a birer uniqe "node id" verilmelidir. Node tanımlarken birde her node için "votes" parametresi verilir. Bu değer integer bir sayı olmak zorundadır. Yeri gelmişken voting ne işe yarar değinelim.
Cluster yapılarında sunulan servislerin hangi şartlar altında çalışmaya devam edeceğini belirlemek için bazı yöntemler vardır. Bunlardan bir tanesi "quorum" mekanizmasıdır. Cluster'a dahil olan her node'a konfigürasyonda belirtilecek miktarda oy hakkı verilebilir. Quorum sayısı o cluster'a dahil olan nodeların "votes" sayılarının toplamının yarısından bir fazlasıdır. Bütün cluster ancak ve ancak quorum sayısı sağlandığı sürece hizmet vermeye devam edebilir. Eğer quorum sayısının altında kalınırsa cluster servis vermeyi sonlandırır. İşte "votes" parametreside her node'un quorum üzerindeki ağırlığını belirler. Bunu bir örnekle açıklamak gerekirse. Örneğin toplam 4 node'dan oluşan bir cluster yapısı kurdunuz. Ve bu node'lardan 3 tanesinden her biri front end işlemleri gerçekleştiriyor. Yani kullanıcı isteklerini karşılamak gibi. Son node ise gelen istekleri disk üzerinde işleyip kullancılara cevap dönmesi için ilk node'a gönderiyor. Böyle bir yapıda front end node'lardan bir tanesininde bir problem yaşanması durumunda ikinci node devreye girerek çalışmayı sürdürebilir. Ancak dördüncü node'un yedeği olmadığı için bu node çalışamaz duruma gelirse bütün servisin durması gerekir. Bu gibi durumlarda votes devreye girer ve sistem yöneticisi bu node'un quorum votes'unu diğerlerinden yüksek belirler.

Yukarıdaki konfigürasyona göre quorum sayısı 4 olduğundan front end node'lardan herhangi birinin veya ikisinin devre dışı kalması durumunda cluster servis vermeye devam edecektir. Eğer üç node da devre dışı kalırsa front end sunucu kalmayacağından ve quorum sayısı kaybedileceğinden cluster kapanacaktır. Eğer dördüncü node devre dışı kalırsa normal olarak cluster'ın hizmet vermemesi gerekir. Bu durumda iken quorum kaybedileceğinden cluser servisleri de kapatılacağı için amacımıza ulaşmış oluyoruz. Umarım açık bir şekilde anlaşılabilmiştir. :)
Quorum sayısı yine cluster.conf dosyasında parametrik olarak belirtilebilir. Bu konfigürasyonda expected_votes=6 ile quorum sayısnın 4 olduğunu belirtiyoruz. Eğer bu parametre verilmezse cluster'a ait tüm node'ların votes değerlerinin toplamınının yarısının bir fazlası quorum sayısı olarak belirlenir.

Bu durumu açıkladıktan sonra biz yine kendi ortamımıza dönelim. Kendi ortamımız iki node'dan oluştuğu için özel bir durumla karşı karşıyayız. Normalde node'lardan bir tanesi devre dışı kaldğınıda quorum kaybedileceği için cluster servislerinin tamamen kapanması gerekir. Bu durumun önüne geçmek için oluşturulmuş "two_node" parametresi kullanılır .Eğer "two_node=1" ise iki node için quorum sayısı aranmaz ve bir node işlem dışı kaldığında diğer node çalışmaya devam eder.

Node tanımlamalarımızı yaptıktan sonra node'lar arası cluster haberleşmesinin nasıl yapılacağını belirtiyoruz. Bunun için cluster.conf dosyasına aşağıdaki satırlar eklenmelidir.

Cluster node'ları birbirleri arasında haberleşmeyi multicast protokolüne göre yaparlar. "multicast addr" parametrsi multicast yayının hangi multicast adresi üzerinden yapılacağını belirtir. Bu alana 224.0.0.0 dan 239.255.255.255'e kadar (bazı istisna adresler hariç!) olan ip aralığından bir adres verilebilir. Önemli olan tüm node'lara aynı adresin verilmesi gerektiğidir. "Port" parametresi multicast dinlemelerinin yapılacağı port numaraısının belirlendiği alandır. Öntanımlı olarak 5405 ve 5404 portları kullanılır ancak yukarıdaki konfigürasyona göre 6809 ve 6808 kullanılacaktır. "Cluster id" ise aynı ortamda çalışan birden fazla cluster yapısı var ise bu yapılarının oluşturduğu cluster veri trafiğinin birbirine karışmaması için verilen bir id'dir. Eğer konfigürasyonda bir multicast adresi belirtilmezse sistem "cluster id" bilgisinden faydalanarak 239.192.X.X şeklinde bir multicast adresi kullanarak haberleşmesini gerçekleştircektir. Bu nedenle "cluster id" konfigürasyonda mutlaka tanımlanmalıdır.
Bununla beraber cluster node'ları birbirleri arasında TOTEM adı verilen TOKEN tabanlı karmaşık bir algoritma ile haberleşerek durumlarını kontrol ederler. Burada "totem" içersindeki "token" parametresinde belirtilen ms süre boyunca node diğer cluster node'larına cevap veremez ise node çalışamaz durumda varsayılır ve fail over yani pasif node'un devreye girmesi prosedürü başlatılır.

Burada belirtilen 33000 değeri ms cinsinden bir node'un ne kadar süre tepksisiz kalabileceğini belirtmiştir. 33 sn sonra node için fail-over işlemi başlatılır.
Fail-over prosedürünün ilk adımı fence işlemidir. Fence işlemi bazı dağıtımlarda stonith (shoot the other node in the head) olarak da geçer. Fence kısaca tanımlanırsa; belirtilen paramaterelere göre hatalı çalıştığı düşünülen node'un, çalışmasının sonlandırıldığından emin olamak ve aynı anda iki node üzerinde aynı kaynağın çalışmamasının garanti edilmesi için çeşitli yöntemler kullanılarak devre dışı bırakılmasıdır. Bu yöntemlerin çoğu node tarafından kullanılan 3. şahıs donanımlar veya yazılımlar vasıtasıyla gerçekleştirilir. Örneğin HP sunucuların bir çoğunda sunucuyu yönetmek için iLO uygulaması vardır. Bu uygulamaya network üzerinden bağlanılarak sunucuyu işletim sisteminden bağımsız kapatma açma veya yeniden başlatma ve bazı yönetim işlemleri yapılabilir. Bu işlem için gerekli tek şey sunucu üzerinde güç olması ve iLO servisine network üzerinden ulaşılabilmesidir. Bu sayede node üzerinde olağan dışı bir durum gerçekleşirse diğer node'lar iLO servislerinden faydalanarak bu sunucuyu devre dışı bırakabilirler. Sunucuda güç problemi olması durumunda sunucuya gömülü olan bu yazılıma ulaşılamayacağı için fence işlemi başarılı olamaz. Fence işleminin başarısız olması durumunda da sunucunun fail over işlemi tamamlanamaz. Fail over işleminin sonucu olumsuz ise kaynakların sorunsuz sonlandırımamaması olasılığından ötürü diğer node'lar devreye giremez ve cluster işlevsiz kalır. Bu nedenle kullanılacak fence metodları iyi belirlenmeli ve mümkünse birden fazla fence metodu kullanılmalıdır. Fence işlemi cluster'ın sağlıklı çalışması açısından çok önemlidir.
Fence işlemi çeşitli donanımlar için yazılmış hazır fence ajanları tarafından gerçekleştirilir. Node'lar için kullanılan donanınmlara göre uygun fence araçları seçilerek konfigüre edilebilir. Genelde iki tür fence ajanı mevcuttur. Bunların ilki hata veren node'u kapatarak yada yeniden başlatarak devre dışı bırakmaya çalışırken diğeri node bağlı olduğu SAN switch portunu kapatmak gibi veri haberleşmesinin önüne geçerek node etkileşimini durdurmaya çalışır. Sistemde hangi fence ajanlarının yer aldığını görmek için aşağıdaki linkten faydalanabilirsiniz.
Biz bu makalede genel olarak mimari üzerinde durmaya çalıştığımız için hazır bir fence ajanı kullanmaktansa gelin kendi fence ajanımızı oluşturmaya çalışalım. Üstelik yukardaki listede yer almayan bir sunucu yada donanım kullanıyorsanız bu çok daha yararınıza olacaktır.
Fence ajanları basit olarak bir Linux programıdır. Bu program shell, perl, python gibi script dilleri ile yazılabileceği gibi tamamiyle C'de derlenmiş bir program da olabilir. Bir fence ajanını çalıştırmak için shell de program adını yazdığınızda çalışabilen bir program olması yeterlidir. Bu nedenle kendi fence ajanınızı /bin altına kopyalamak doğru bir hareket olacaktır. Öncelikle elimizde uygun bir fence edebilecek bir aygıt olmadığını ve test amaçlı bir cluster yapısı kurduğumuzu ve fencing'e şimdilik ihtyaç duymadığımızı varsayarsak (ki bu kesinlikle tavsiye edilmez) basit bir ajan işimizi görecektir. Bunun için aşağıdaki gibi çok basit bir shell scripti hazırlayabiliriz.

Bu scripti hazırladıktan sonra her iki node'da /bin klasörü altına kopyalamalı ve aşağıdaki komutu çalıştırmalısınız.
Bir fail-over anında ayakta kalan node kendi bin klasöründe yer alan
dummyfence programını çalıştıracak ve programdan "0" değeri döndüğü
için diğer node'un başarıyla fence edildiğini düşünerek servisleri kendi
üzerinde çalıştırmaya başlayacaktır. Oluşturduğumuz bu dummyfence'i
konfigürasyona eklemek için aşağıdaki bilgiler kullanılabilir.

Bu konfigürasyonla beraber herhangi bir hata durumunda fail-over işlemi sırasında ayakta kalan node nodedown isimli dummyfence aygıtını parametre1 ve parametre2 değerleri ile çalıştırarak diğer node'u devre dışı bırakmaya çalışır. Bu işlem başarılı olursa servisleri kendi üzerinde alarak devamlılığı sağlayabilir. paramtere1 ve parametre2 kendi fence ajanımızın nasıl çalışacağını belirlemek için kullanabilir. İlk dummyfence ajanı için bu değerler bir anlam ifade etmeyecektir. Biraz daha karmaşık bir fence ajanı yazmayı deneyelim.

Bu shell scripti incelendiğinde bazı detayla göze çarpacaktır. Normalde cluster yazılımı herhangi bir fence ajanına parametre gönderirken STDIN'i kullanır. Kendi konfigürasyonumuza göre gidersek fence agent'a STDIN üzerinden aşağıdaki formata göre konfigürasyonda verilen paramtreler gönderilir.
Haızrladığımız script gönderilen bu bilgiden ip1 ve name parametreleri ayıklanacak şekilde yazılmıştır. Örneğimizde parametre1 node'umuzun servis parametre2 de node'umuzun interconnect ip'sidir. Script'te gönderilen bütün paramtere bloğu stdin'den okunarak parse edilmeye ve device'ların hem interconnect ipleri hemde servis ipleri elde edilmeye çalışılmaktadır. Daha sonra bu bilgilerden faydalanarak hata veren node'u iki thread çalıştırarak reboot etmeyi denyecektir. Biraz ilkel gibi görünsede fence mekanizmasının nasıl çalıştığının alnlaşılması açısından önemli bir örnektir. Yukarıdaki fence ajanına göre bizim konfigürasyon dosyamız aşağıdaki gibi olmalıdır.

Fence işlemini de açıkladıktan sonra cluster mimarisindeki temel bir sorundan bahsetmek istiyorum. Özellikle iki node'lu cluster modellerinde interconnect bağlantıların öneminden daha öncede bahsetmiştik. Açıklamaya çalıştığımız sorun da interconnect ile ilgili ve şu şekilde oluşuyor. Herhangi bir sebeple cluster interconnect'indeki veri haberleşmesi sağlanamazsa ne olur? (Örneğin kullandıkları VLAN taglerinin karışması gibi). Buraya kadar anlattıklarımızdan yola çıkarsak şunu söyleyebiliriz. Kendi konfigürasyonumuza göre 33 sn boyunca TOKEN paylaşımı olmayacağı için her iki node'da diğerinin devre dışı kaldığını zannedecek ve birbirlerini fence etmeye çalışacaklardır. Yani cluster node'ları birbirlerini aynı anda reboot etmeye çalışacaklardır. Bu gibi hangi cluster node'unun gerçekten ayakta olup olmadığının anlaşılmaması durumuna "split brain" adı verilir. Split brain iki node'lu cluster'lar için aşılması güç bir durumdur. Hatta ortak disk kullanımı imkanı olmayan sunucularla oluşturulmuş modellerde bundan kurtulmanın tek yolu konfigürasyona üçüncü bir node eklemektir. Biz kendi kofigürasyonumuzdan gidersek split brain'den kaçınmanın başka bir yolunu kullanabiliriz. Bu da quorum disk kullanmaktır. (Bazı yerlerde tie break olarak da geçebilir.).
Quorum disk temel olarak her iki cluster node'u için disk üzerinden haberleşme sağlamak amacıyla oluşturulmuş bir mekanizmadır. Cluster node'ları birbirleriye hem interconnect üzerinden hemde ortak disk paylaşımı üzerinden haberleşerek cluster'ın durumu hakkında bilgi edinebilirler. (Daha çok eski sürmler için bu durum geçerliydi ancak yeni sürümlerle beraber bu mekanizma değişti. Bu mekanizma artık node'ların network servisinin yanında disk servisininde kontrol edilmesi için kullanılıyor. Biz yine de açıklamaya çalışalım.)
Quorum disk kullanımı için cluster node'ların herhangi birinden quorum için oluşturulmuş (Bizim örneğimizde 1 GB'lık disk) diski aşağıdaki komut ile uygun formata çevirebiliriz.

Komutun ekran çıktısından da anlaşılacağı üzere 16 node'a kadar quorum
disk üzerinden haberleşme gerçekleştirebilir. Quorum disk'ini konfigürasyona
aşağıdaki gibi ekleyebiliriz.

Burada quorum altındaki paramatreleri açıklamamız gerekir. Öncelikle "interval" parametresi quorum diskine kaç saniyede bir kontrol verisinin yazılacağını belirler. "device" paramteresi her iki node'dan erişilebilen diskin udev ismidir. tko (technical knock-out) parametresi kaç "interval"den sonra node'un devre dışı sayılacağını belirtir. Buna göre toplma 6 sn boyunca quorum diskine erişemeyen node devre dışı sayılacaktır. "votes" quorum disk erişiminin quorum sayısındaki ağırlığını gösterir.Bu konfigürasyon üzerinden konuşursak cluster yapısında hem online görününen hemde quorum diske yazabilen node iki oy hakkına sahiptir. İki node'lu cluster yapılarında eğer quorum disk kullanılıyorsa qourum sayısını belirleyen konfigürasyon parametreleri aşağıdaki şekilde değiştirilmelidir.
Ancak bu konfigürasyon da split-brain durumunu çözmez. Çünkü her iki node da hem diske erişip hemde kendini online görüyor olabilir. Bunu çözmek için de başka bir parametre devreye girer. Bu parametre "master_wins" dir. Quorum disk mekanizmasında diske erişimi olan bütün node'lardan yalnızca 1 tanesi master olarak seçilir. Eğer master_wins paramteresi =1 yapılırsa quorum diskine erişimi olan node'lardan yalnızca master olarak işaretlenen node, quorum sayısının belirlenmesinde quorum diskinin oy hakkını kullanabilir. Diğer node diske erişebilese bile quorum sayısının belirlenmesinde quorum disk erişimini kullanamaz. Ancak eğer quorum disk master'ı diske erişimini kaybederse diğer node master olarak seçilir ve quorum sayısındaki oy hakkı ona geçer . Bu durumda quorum sayısı sağlanabildiği için cluster hizmet vermeye devam edebilir. Doğru olan konfigürasyon aşağıdaki gibi olmalıdır.

Quorum disk iki node'lu cluster'larda split-brain'den kaçınmak için kullanıldığı gibi bazen de cluster'ın durumunun kesinlik kazandıırlması amacıyla kullanılabilir. Yani node üzerinde network servisleri çalışabiliyorken aynı node SAN üzerinde sorun yaşıyor olabilir. Bu durumda node quorum disk erişimini kaybedeceğinde offline konumuna düşer ve diğer node'lar tarafından fail-over prosedürü başlatılabilir. Cluster mimarinizin düzgün çalışması açısından her durumda quorum disk kullanmakta fayda vardır.
Son olarak quorum ile ccsd servislerinin birbirleri ile ilişkili çalışması için aşağıdaki parametreyi konfigürasyonumuza eklemeliyiz. Bu parametre sayesinde cluster servisi uorum servisini her 33 sn. bir kontrol edecektir.

Buraya kadar cluseter servisleri için gerekli tüm konfigürasyonu tamamlamış olduk. Bundan sonra cluster üzerinden verilecek servisler için bazı düzenlemeler yapacağız. Ama önce cluster'ımız düzgün çalışıyor mu kontrol edelim.
Cluster'ımızı başlatmak için her iki node da aşağıdaki komutları yazmamız gerekir.


Bu seviyede aşağıdaki komut ile cluster durumunu gözlemleyebilirsiniz.


Yukarıda görüldüğü üzere yalnızca quorum disk uygulamasında master olan node için quorum disk online görünür. Şimdi ufak bir test yapalım. Cluster node'lardan birtanesinin (özellikle quorum diskte master role olanı) inteconnect network'ünü kapatıp neler oluyor gözlemlemleyelim.

Bunun için sanal makinemizin donanım ayarlarında network bağlantı portunu kapatmalıyız. Tam olarak 33 sn. sonra cluster'ımız yapılan bu değişikliğe tepki verecek ve diğer node'u yazdığımız fence device ile restart etmeyi deneyecektir. İşlem sonunda her iki node'un loglarında aşağıdaki bilgiler yer alacaktır.


Özellikle ikinci node'un loglarında görülen " quorum lost, blocking activity" mesajı split brain'in nasıl engellendiğinin anlaşılması açısından önemlidir.
Bu işlemden sonra ikinci node'umuz yeniden başladıktan sonra network ayarları düzeltilip cluster servisleri yukarıda anlatılan şekilde yeniden başlatılmalıdır.
Buaraya kadar cluster'ımızın çalışması için gerekli mininmum konfigürasyon tamamlanmıştır. Bundan sonra cluster üzerinden verilecek hizmetleri düzenleyeceğiz. Makalenin başlığında da görüldüğü gibi cluster'ımız üzerinde oracle servisinin çalışacak şekilde konfigüre edilecektir. Oracle servisinin çalışması için temel olarak üç kaynağa ihtiyacımız vardır. Bunlardan ilki IP adresidir. cluster üzerinde IP servisinin tanımlanması aşağıdaki gibi yapılabilir.

Burada görüldüğü gibi kullanılacak tüm kaynaklar "resource" tag'inde tanımlanabilir. Kullanacağımız ilk kaynak ip adresi bu şekilde tanımlanır. Verilen IP adresi istemcilerin cluster hizmetlerine ulaşırken kullanacakları ip adresidir. "monitor_link" parametresi ise verien ip adresinin erişilebilir olup olmadığının cluster tarafından takip edileceği belirtilir. Burada ip adresine erişimde herhangi bir sıkıntı olması durumunda (örneğin network interface'i için unplugged durumu) cluster otomatik olarak fail-over durumunu başlatacaktır. Ancak diğer fail-over durumundan faklı olarak aktif node üzerindeki servisleri kontrollü olarak diğer node'a geçireceği için herhangi bir fence işlemine gerek duyulmayacaktır. Cluster'da kaynak olarak IP adresi tanımlandıktan sonra servis tanımlama işlemi aşağıdaki gibi gerçekleştirilir.

Tanımlama yapıldıktan sonra (ve her cluster.conf dosyası değişikliğinde) diğer node ile konfiügrasyon eşitlemesi yapılmaldır. Bunun için aşağıdaki komuttan faydalanılabilir.
Servis başlatıldıktan sonra "clustat" komutu ile cluster'ların
durumu kontrol edilmelidir:


Görüleceği üzere servisimiz node1 üzerinde aktif durumda çalışmaktadır. Verdiğimiz IP hizmetinin çalışıp çalışmadığını kontrol etmek için basit olarak ping paketleri gönderebiliriz.

Bu aşamadan sonra yine küçük bir test yapalım ve ping servisinin çalıştığı sunucuyu konrolsüz bir şekilde power off edelim. (Yani sunucunun elektriğini keselim) ve cluster'ın davranışını gözlemleyelim.



Yukarıdaki ekran çıktıları incelendiğinde önce kapatılan node'un cluster içersinde offline'a düştüğünü, 33 sn sonra diğer node'un servisi kendi üzerinde çalıştırmaya başladığını görüyoruz. Geçen bu süre ip servisinin hizmet veremediğini ve ikinci node'da servis çalışmaya başladıktan sonra ping paketleri için cevap alabildiğimizi görmekteyiz.
Cluster’ımıza tanımlayacağımız ikinci hizmet ise Oracle instance’ının çalışacağı file system’dir. Bu file system için makalenin başında belirtilen şekilde ortak bir disk alanı ataması yapılmalıdır. Lvm konularına girmemek için şimdilik basit bir şekilde ortak diskimize fdisk yardımıyla partition oluşturup mkfs.ext3 komutu ile file system yapısını oluşturuyoruz. Bu alan yine makalenin başında belirtildiği gibi Oralce Enterprise sürümü için en az 5 GB olmalıdır (> 4,6 GB)
Oluştuduğumuz bu file system’i resource manager tag’inde aşağıdaki parametreler ile tanımlamamız gerekiyor.

Burada verien parametrelerin en önemlileri “device” ve “mountpoint” dir. Bu iki parametreyi kendi sistemimize uygun olacak şekilde düzenledikten sonra service tag’inde aşağıdaki düzenlemeleri yapmalıyız.

Bu iki değişikliği de yaptıktan sonra cluster.conf dosylarını her iki node’da da eşitlemeliyiz. Ve sonrasında herşeyin çalıştığından emin olmak için cluster servislerini yeniden başlatıp küçük bir test yapabiliriz. Eğer cluster servislerini yeniden başlatmak istemiyorsanız cluster.conf dosyasında yer alan “<cluster name="testcluster" config_version="1">” satırındaki “config_version” parametresinin değerini nteger olarak bir artırdıktan sonra dosyayı kaydedip diğer node ‘la eşitledikten sonra aşağıdaki komut yardımıyla konfigürasyon güncellemesi yapabilirsiniz.
komuttdan sonra df –h komutu ile oluşturduğumuz file system’in aktif olan
node’da otomatik olarak mount edildiğini görebiliriz.

Eğer herhangi bir sebeple çalışan servislerin diğer node üzernden hizmet vermesini istiyorsak aşağıdaki komutu kullanabiliriz.

Eğer hazırlanan servis otomatik olarak başlamıyorsa aşağıdaki komut yardımı
ile servisi başlatabiliriz.

Eğer çalışan servisi durdurmak istiyorsak aşağıdaki komutu kullanabiliriz.

Buaraya kadar yaptıklarımız işin altyapı boyutunu kapsıyordu. Şimdi sıra
geldi oluşturduğumuz bu altyapı üzerine Oracle uygulamamızı yerleştirmeye.
Oracle kurulumu için resmi oracle sitesinden 64 bit Linux versiyonunu
indirebilirsiniz. İlgili link aşağıdadır.
İndirme işlemi tamamlandıktan sonra aşağıdaki linkte verilen işlem adımlarına uygun olarak Oracle kurulumlarını gerçekleştirebilirsiniz.
Kurulum işelmeri tamamlandıktan sonra Oracle ile Cluster yazılımının birlikte çalıştırılması işlemlerini gerçekleştireceğiz. Bunun için Cluster suit yazılımıyla beraber gelen hazır template’ler kullanılabiliriz. Ancak biz bu makalede mimariyi anlatmaya çalıştığımız için hazır template kullanmak yerine kendi scriptimizi yazacağız. Bu script temel olarak Oracle DB sini başlatacak, sonlandıracak ve durumunu kontrol edecektir.
Resource Manager tarafından kullanılacak her script tipindeki kaynağın LSB uyumlu yazılması gerekmektedir. Başka bir deyişle hazırlayacağımız script temel olarak”start”, “stop”, “status”, “monitor” parametrelerine cevap verebiliyor olması gerekir. Bunun için ilk olarak Oracle başlatma scriptimizi aşağıdaki gibi hazırlamalıyız.

Scripti genel olarak incelendiğmizde son derece basit yapılandırılmış olduğunu görebiliriz. Burada il olarak standart oracle shell değişkenlerinin tanılanmasından sonra oracle’a startup komutunu gönderip daha sonra Enterprise Manager (dbconsole) ve Listener’ı (lsnrctl) çalıştırıyoruz.
Hazırlamamız gereken ikinci script ise Oracle durdurma scriptidir. Bu script’de aşağıdaki gibi hazırlanabilir.

Bu scripte yukardıkaine benzer olarak basitçe database’e shudown komutu göndermektedir.
Hazırlamamız gereken üçüncü script ise status için kullanılacaktır. Status Cluster Suit yazılımı tarafından belirli periyotlarda çalışan uygulamanın durumunu konrol etmek için kullanılır. Bu scriptin sonucuna göre uygulamanın çalışıp çalışmadığına karar veren Cluster yazılımı sonuca göre fail-over işlemini gerçekleştirir. Bizim hazırladığımız script temel olarak Oracle üzerinde kopmlex olmayan bir sorgu çalıştırıp sonuç aldığında geriye “0” değeri, sonuç alamadığı zaman da geriye “1” değeri göndererek Cluster yazılımına uygulamanın durumu hakkında bilgi vermektedir. Script aşağıdaki şekilde yazılabilir.

Burada script basit olarak execsql.sql isimli sql script dosyasını veritabaı üzerinde çalıştırır. Execsql.sql sql script dosyası aşağıdaki gibidir.

Bu scriptleri tamamladıktaon sonra sıra Cluster yazılımı tarafından kullanılacak asıl scripte geldi. Bu scriptide yukarıda belirttiğimiz gibi bazı temel parametrelere cevap verebilmek için hazırladığımız alt scriptleri çalıştıracak bir çatı scriptidir.
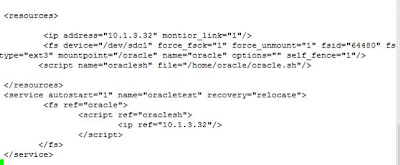
Oracle çalışmadan IP servisinin başlatılmasının anlamı olmayacağı için ip resource’uda bu service tree’ye eklenmiştir.
Tüm bu konfigürasyonlar tamamlandıktan sonra cluster.conf eşitlemesiyle beraber her iki node için de /home/oracle klasörlerininde eşitlenmesi gerekiyor.
Bütün bu düzenlemelerden sonra cluster’ımız hazır görünüyor. Sıra geldi bu yapıyı test etmeye. Tüm cluster configürasyonlarını update ettikten sonra servisleri enable edip clustat ile cluster’ımızın durumunu kontrol ediyoruz.

Burada oracle kullanıcısı ile sqlplus çalıştırıp basit bir sorguyla sistemimizi test edebiliriz.

Şimdi servisin çalıştığı ilk node’u kontrolsüz olarak kapatalım ve sonuçları izleyelim.



İlk node’da yaptığımız testi ikinci node’da da gerçekleştirerek Oracle’ımızın sorunsuz çalıştığını görebiliriz.
Makale genelinde genel mimari ve çalışma presipleri üzerinde duruduğumdan clvm gibi daha ayrıntılı konulara pek girmedim. Cluster’ın tam anlamıyla sağlıklı çalışması için bazı ayrıntılar üzerinde de durmak gerekiyor ancak konuyu fazla uzatmamak adına bu çalışmayı burada sonlandırmayı tercih ediyorum. Umarım buradaki bilgiler işinize yarayacak türdendir. Başka bir makalede görüşmek üzere...
Uzun bir zamandır burada paylaşımda bulunmadığımın farkettim. Bu nedenle geniş ve kapsamlı bir makale oluşturmaya karar verdim. Bu makalede RedHat Enterprise Linux 5.8 üzerinde Oracle 11gR2 için aktif-pasif cluster kurulumunun nasıl yapılacağını anlatmaya çalışacağım. Başlamadan önce bazı temel terimlere değinmekte fayda olacağını düşünüyorum. Öncelikle cluster'ın ne olduğuna değinmekle başlayabiliriz. Basit olarak cluster bilişim sistemleri üzerinden verilen servislerin mümkün olduğunca kesintisiz hizmet vermesi için, birden fazla öğenin bir araya getirilmesiyle oluşturulmuş bir çalışma modelidir. Birden fazla yöntemi olan bu yapının en çok kullanılan yöntemleri aktif-pasif ve aktif-aktif'dir.
Aktif-Pasif cluster yönteminde, servis aynı anda yalnızca bir cluster üyesi üzerinde çalışabilir. Bu üyeye aktif üye denir. Diğer üyeler bu servisi veren üyeyi belirli periyotlarla kontrol eder ve gerektiğinde belirlenen aksiyonları alır. Bu üyelere de pasif üye denir. Servis aynı anda yalnızca tek bir sunucu üzerinde çalışacağından paylaşılmış kaynaklara ihtiyaç duyulmayabilir. RHEL Cluster Suit aktif-pasif için bir örnek olabilir.
Aktif-Aktif cluster modelinde ise servis birden fazla üye üzerinde aynı anda çalışır. Bu çalışma belirlenen kurallara göre gerçekleşir. Genelde amaç servis devamlılığıyla beraber yük paylaşımıdır. Servis için ortak kaynaklar kullanılacağından toplam sistem performansı Xn sistemlerin toplam performansından küçük olabilir. Üyelerin herhangi birinde oluşabilecek bir problemde servis üzerinde herhangi bir kesinti yaşanmaz ancak servis kalitesinde değişim yaşanabilir..Oracle Real Application Cluster Aktif-Aktif cluster'a örnek gösterilebilir.
Cluster yapısındaki sunucuların her birine "node" denilir. Node'ların cluster işlemleri için birbiri ile haberleştikleri ve ortamdaki diğer ağlardan yalıtılmış ağlara "cluster network" yada "interconnect" denir. Cluster üzerinde çalışan ve kullanıcıların taleplerini karşılayan programlara da servis denilebilir.
Temel konulardan bahsettikten sonra kendi çalışmamızdan söz edebiliriz. Öncelikle bu çalışma için kendi kurulum yaptığım ortamı anlatmak istiyorum. Bu çalışmayı ESX 4.1 üzerinde kurulmuş olan iki adet RHEL 5.8 sanal sunucu üzerinde gerçekleştirdim. Kurulan bu sunuculara iki adet NIC kartı ekledim. Bu kartlardan bir tanesi servis IP'si için diğeride cluster interconnect'i için kullanıldı. Genelde iki node'lu cluster'lar için bu model kullanılır. İkinci olarak sunucular üzerinde oracle çalışacağı için bazı ortak kaynakları da belirtmemiz gerekiyordu. Bu nedenle oracle kullanımı için her iki sunucununda kullanabileceği disk ataması yaptım. Normalde bu işlem SAN bağlantısı olan fiziksel sunucular üzerinde oldukça kolay yapılabilir. Ancak ESX üzerinde bazı özel konfigürasyon yapmak gerekir. Ortak disk atamasıilk node'a aşağıdaki gibi yapılır. Atama yaparken dikkat edilmesi gereken şey scsi id'sini OS diskinden faklı bir scsi id vermektir. Bu haliyle aşağıdaki şekilde görüldüğü gibi kullanılacak disk için ESX tarafından başka bir scsi device tanımlanması sağlanır. Yeni oluşan scsi device'ın özelliklerinden "Scsi Bus Sharing" Physical'a getirilerek oluşturulan bu diskin ESX üzerindeki başka sunucular tarafından da kullanılabilmesi sağlanır.


İkinci node'a da aynı diski göstermek için add harddisk dedikten sonra ilk "Use existed drive" seçeneği seçilir. Diğer node için yanımlanan disk "Storage" lar üzerinden bulunarak eklenir. Bu disk içinde ilk node için belirtilen aynı scsi id kullanılmalıdır. Oluşan yeni scsi device içinde aynı ayarlar yapıldıktan sonra sunucular üzerinde aşağıdaki komutlar root kullanıcısı ile kullanılarak disklere erişimler başlatılmaıldır.
cd /sys/class/scsi_host
for i in $(ls)
do
echo "- - -" > /sys/class/scsi_host/ $i/scan
done
{kind=link}
Bu komutları her iki node'da çalıştırdıktan sonra fdisk -l ile disklerin node üzerindeki durumu kontrol edilir.


Burada sonradan değineceğimiz konular olduğu için ayrıntılara çok yer vermedim. Ancak standart Oracle 11g kurulumu için yaklaşık 4.5-5 Gb lık bir disk alanı ve Quorum içinde minimum10 Mb'lık disk alanına ihtiyacımız olacak. 10MB'lık LUN lar bazı storage'lar için sorun teşkil edeceğinden sizde 1 GB'lık bir alan oluşturuabilirsiniz. Bu alanları yukarıda belirtildiği gibi paylaşımlı olarak yani her iki node'un bu alanlara erişimi olacak şekilde oluşturmalısınız.
Bu işlem tamamlandıktan sonra gelelim RHEL Cluster Suit kurulumuna. Bunun için RHEL paket yöneticisi yum'dan faydalanacağız. Ancak RHEL cd'lerinde Cluster Suit yazılımları standart kütüphaneden farklı bir klasörde yer aldığı için yum repository'sini güncellemeniz gerekecek. Cluster Suit kurulumu için aşağıdaki komutu kullanabilirsiniz.
yum -y groupinstall "Clustering" " Cluster Storage"
Kurulum tamamlandıktan sonra biraz RHEL cluster yapısına değinmek istiyorum. RHEL cluster yapısında temel olarak 3 kernel module'ü (configfs, dlm, lock_dlm) ve 5 adet service'den (ccsd, groupd, fenced, dlm_controld, gfs_controld) oluşur. Bu servislerden en önemlisi ccsd'dir. Bu servisler cluster yapısından ve cluster'ın sağlıklı çalışmasından sorumludur. Bunun dışında cluster tarafından verilecek hizmetleri yöneten 1 adet (clurgmgrd), cluster durumunu kontrol etmekte faydalanılan 1 adet (quorumd) servisi de cluser içerisinde kullanılır. Cluster'a iat tüm konfigürasyon aşağıdaki xml formatlı dosya ile yürütülür.
Cluster kurulumu ve konfigürasyonunun tamamı bu dosya altından yürütülür. İlk paket kurulumları tamamlandıktan sonra aşağıdaki komut yardımıyla boş ve formatlı bir cluster.conf dosyası oluşturulabilir./etc/cluster/cluster.conf
Burada cluster name'imizi testcluster olarak belirtiyoruz. Komut sonrasında /etc/cluster altında aşağıdaki gibi bir cluster.conf dosyası oluşacaktır.ccs_tool create testcluster

Bütün konfigürasyon işlemleri bu dosya üzerinden yönetilecektir. Şimdi ilk olarak cluster node'larımızı ekleyelim. Bunun için dosyası herhangi bir metin editörü ile açıp aşağıdaki satırları ekleyebiliriz.

Burada iki node'lu bir cluster oluşturuyoruz. Node name olarak cluster interconnect ip'lerini kullanmalıyız (İsterseniz hostname 'de kullanabilirsiniz. Ancak DNS kullanıyorsanız IP üzerinden gitmekte fayda var). Cluster'ın çalışması için interconnect network'u kullanmak zorunlu değil ancak sağlıklı çalışması için gereklidir. Cluster node'ları birbirleri arasındaki token'ları bu interconnect üzerinden göndererek diğer sunucuların çalışıp çalışmadığını kontrol edebilirler. Bu haberleşmede oluşabilecek herhangi bir sorun tüm cluster node'larının işlevsiz kalmasına yol açabilir. Best practice'lerde eğer mümkünse bu bağlantıların diğer ağ bağlantılarında yalıtılmış ortamlar üzerinden gerçekleşririlmesi gerektiği belirtilir. Eğer iki node'lu bir cluster kullanacaksanız bu bağlantı için back to back veya cross kablo ile bağlantı da önerilmez. Bunun nedeni cross kablo ile birbirine bağlı iki node'dan bir tanesi kapatıldığında diğer node kendi bağlantısınında "unplugged" olduğunu zanneder ve cluster yapsını kaybettiğini düşünerek servisleri kapatabilir. Eğer bağlantı switch üzerinden sağlanırsa bir node kapatılsa bile diğer node switch üzerinden kendi network'unun ayakta olduğunu anlayabilir. Bu bağlantının önerilmemesi için başka bir neden daha var ancak bu konuya makalenin ilerleyen safhalarında değineceğiz.
Node name'lerle beraber cluster internal işlemleri için her node'a birer uniqe "node id" verilmelidir. Node tanımlarken birde her node için "votes" parametresi verilir. Bu değer integer bir sayı olmak zorundadır. Yeri gelmişken voting ne işe yarar değinelim.
Cluster yapılarında sunulan servislerin hangi şartlar altında çalışmaya devam edeceğini belirlemek için bazı yöntemler vardır. Bunlardan bir tanesi "quorum" mekanizmasıdır. Cluster'a dahil olan her node'a konfigürasyonda belirtilecek miktarda oy hakkı verilebilir. Quorum sayısı o cluster'a dahil olan nodeların "votes" sayılarının toplamının yarısından bir fazlasıdır. Bütün cluster ancak ve ancak quorum sayısı sağlandığı sürece hizmet vermeye devam edebilir. Eğer quorum sayısının altında kalınırsa cluster servis vermeyi sonlandırır. İşte "votes" parametreside her node'un quorum üzerindeki ağırlığını belirler. Bunu bir örnekle açıklamak gerekirse. Örneğin toplam 4 node'dan oluşan bir cluster yapısı kurdunuz. Ve bu node'lardan 3 tanesinden her biri front end işlemleri gerçekleştiriyor. Yani kullanıcı isteklerini karşılamak gibi. Son node ise gelen istekleri disk üzerinde işleyip kullancılara cevap dönmesi için ilk node'a gönderiyor. Böyle bir yapıda front end node'lardan bir tanesininde bir problem yaşanması durumunda ikinci node devreye girerek çalışmayı sürdürebilir. Ancak dördüncü node'un yedeği olmadığı için bu node çalışamaz duruma gelirse bütün servisin durması gerekir. Bu gibi durumlarda votes devreye girer ve sistem yöneticisi bu node'un quorum votes'unu diğerlerinden yüksek belirler.

Yukarıdaki konfigürasyona göre quorum sayısı 4 olduğundan front end node'lardan herhangi birinin veya ikisinin devre dışı kalması durumunda cluster servis vermeye devam edecektir. Eğer üç node da devre dışı kalırsa front end sunucu kalmayacağından ve quorum sayısı kaybedileceğinden cluster kapanacaktır. Eğer dördüncü node devre dışı kalırsa normal olarak cluster'ın hizmet vermemesi gerekir. Bu durumda iken quorum kaybedileceğinden cluser servisleri de kapatılacağı için amacımıza ulaşmış oluyoruz. Umarım açık bir şekilde anlaşılabilmiştir. :)
Quorum sayısı yine cluster.conf dosyasında parametrik olarak belirtilebilir. Bu konfigürasyonda expected_votes=6 ile quorum sayısnın 4 olduğunu belirtiyoruz. Eğer bu parametre verilmezse cluster'a ait tüm node'ların votes değerlerinin toplamınının yarısının bir fazlası quorum sayısı olarak belirlenir.

Bu durumu açıkladıktan sonra biz yine kendi ortamımıza dönelim. Kendi ortamımız iki node'dan oluştuğu için özel bir durumla karşı karşıyayız. Normalde node'lardan bir tanesi devre dışı kaldğınıda quorum kaybedileceği için cluster servislerinin tamamen kapanması gerekir. Bu durumun önüne geçmek için oluşturulmuş "two_node" parametresi kullanılır .Eğer "two_node=1" ise iki node için quorum sayısı aranmaz ve bir node işlem dışı kaldığında diğer node çalışmaya devam eder.

Node tanımlamalarımızı yaptıktan sonra node'lar arası cluster haberleşmesinin nasıl yapılacağını belirtiyoruz. Bunun için cluster.conf dosyasına aşağıdaki satırlar eklenmelidir.

Cluster node'ları birbirleri arasında haberleşmeyi multicast protokolüne göre yaparlar. "multicast addr" parametrsi multicast yayının hangi multicast adresi üzerinden yapılacağını belirtir. Bu alana 224.0.0.0 dan 239.255.255.255'e kadar (bazı istisna adresler hariç!) olan ip aralığından bir adres verilebilir. Önemli olan tüm node'lara aynı adresin verilmesi gerektiğidir. "Port" parametresi multicast dinlemelerinin yapılacağı port numaraısının belirlendiği alandır. Öntanımlı olarak 5405 ve 5404 portları kullanılır ancak yukarıdaki konfigürasyona göre 6809 ve 6808 kullanılacaktır. "Cluster id" ise aynı ortamda çalışan birden fazla cluster yapısı var ise bu yapılarının oluşturduğu cluster veri trafiğinin birbirine karışmaması için verilen bir id'dir. Eğer konfigürasyonda bir multicast adresi belirtilmezse sistem "cluster id" bilgisinden faydalanarak 239.192.X.X şeklinde bir multicast adresi kullanarak haberleşmesini gerçekleştircektir. Bu nedenle "cluster id" konfigürasyonda mutlaka tanımlanmalıdır.
Bununla beraber cluster node'ları birbirleri arasında TOTEM adı verilen TOKEN tabanlı karmaşık bir algoritma ile haberleşerek durumlarını kontrol ederler. Burada "totem" içersindeki "token" parametresinde belirtilen ms süre boyunca node diğer cluster node'larına cevap veremez ise node çalışamaz durumda varsayılır ve fail over yani pasif node'un devreye girmesi prosedürü başlatılır.

Burada belirtilen 33000 değeri ms cinsinden bir node'un ne kadar süre tepksisiz kalabileceğini belirtmiştir. 33 sn sonra node için fail-over işlemi başlatılır.
Fail-over prosedürünün ilk adımı fence işlemidir. Fence işlemi bazı dağıtımlarda stonith (shoot the other node in the head) olarak da geçer. Fence kısaca tanımlanırsa; belirtilen paramaterelere göre hatalı çalıştığı düşünülen node'un, çalışmasının sonlandırıldığından emin olamak ve aynı anda iki node üzerinde aynı kaynağın çalışmamasının garanti edilmesi için çeşitli yöntemler kullanılarak devre dışı bırakılmasıdır. Bu yöntemlerin çoğu node tarafından kullanılan 3. şahıs donanımlar veya yazılımlar vasıtasıyla gerçekleştirilir. Örneğin HP sunucuların bir çoğunda sunucuyu yönetmek için iLO uygulaması vardır. Bu uygulamaya network üzerinden bağlanılarak sunucuyu işletim sisteminden bağımsız kapatma açma veya yeniden başlatma ve bazı yönetim işlemleri yapılabilir. Bu işlem için gerekli tek şey sunucu üzerinde güç olması ve iLO servisine network üzerinden ulaşılabilmesidir. Bu sayede node üzerinde olağan dışı bir durum gerçekleşirse diğer node'lar iLO servislerinden faydalanarak bu sunucuyu devre dışı bırakabilirler. Sunucuda güç problemi olması durumunda sunucuya gömülü olan bu yazılıma ulaşılamayacağı için fence işlemi başarılı olamaz. Fence işleminin başarısız olması durumunda da sunucunun fail over işlemi tamamlanamaz. Fail over işleminin sonucu olumsuz ise kaynakların sorunsuz sonlandırımamaması olasılığından ötürü diğer node'lar devreye giremez ve cluster işlevsiz kalır. Bu nedenle kullanılacak fence metodları iyi belirlenmeli ve mümkünse birden fazla fence metodu kullanılmalıdır. Fence işlemi cluster'ın sağlıklı çalışması açısından çok önemlidir.
Fence işlemi çeşitli donanımlar için yazılmış hazır fence ajanları tarafından gerçekleştirilir. Node'lar için kullanılan donanınmlara göre uygun fence araçları seçilerek konfigüre edilebilir. Genelde iki tür fence ajanı mevcuttur. Bunların ilki hata veren node'u kapatarak yada yeniden başlatarak devre dışı bırakmaya çalışırken diğeri node bağlı olduğu SAN switch portunu kapatmak gibi veri haberleşmesinin önüne geçerek node etkileşimini durdurmaya çalışır. Sistemde hangi fence ajanlarının yer aldığını görmek için aşağıdaki linkten faydalanabilirsiniz.
https://access.redhat.com/knowledge/articles/28603
Biz bu makalede genel olarak mimari üzerinde durmaya çalıştığımız için hazır bir fence ajanı kullanmaktansa gelin kendi fence ajanımızı oluşturmaya çalışalım. Üstelik yukardaki listede yer almayan bir sunucu yada donanım kullanıyorsanız bu çok daha yararınıza olacaktır.
Fence ajanları basit olarak bir Linux programıdır. Bu program shell, perl, python gibi script dilleri ile yazılabileceği gibi tamamiyle C'de derlenmiş bir program da olabilir. Bir fence ajanını çalıştırmak için shell de program adını yazdığınızda çalışabilen bir program olması yeterlidir. Bu nedenle kendi fence ajanınızı /bin altına kopyalamak doğru bir hareket olacaktır. Öncelikle elimizde uygun bir fence edebilecek bir aygıt olmadığını ve test amaçlı bir cluster yapısı kurduğumuzu ve fencing'e şimdilik ihtyaç duymadığımızı varsayarsak (ki bu kesinlikle tavsiye edilmez) basit bir ajan işimizi görecektir. Bunun için aşağıdaki gibi çok basit bir shell scripti hazırlayabiliriz.

Bu scripti hazırladıktan sonra her iki node'da /bin klasörü altına kopyalamalı ve aşağıdaki komutu çalıştırmalısınız.
chmod a+x /bin/dummyfence

Bu konfigürasyonla beraber herhangi bir hata durumunda fail-over işlemi sırasında ayakta kalan node nodedown isimli dummyfence aygıtını parametre1 ve parametre2 değerleri ile çalıştırarak diğer node'u devre dışı bırakmaya çalışır. Bu işlem başarılı olursa servisleri kendi üzerinde alarak devamlılığı sağlayabilir. paramtere1 ve parametre2 kendi fence ajanımızın nasıl çalışacağını belirlemek için kullanabilir. İlk dummyfence ajanı için bu değerler bir anlam ifade etmeyecektir. Biraz daha karmaşık bir fence ajanı yazmayı deneyelim.

Bu shell scripti incelendiğinde bazı detayla göze çarpacaktır. Normalde cluster yazılımı herhangi bir fence ajanına parametre gönderirken STDIN'i kullanır. Kendi konfigürasyonumuza göre gidersek fence agent'a STDIN üzerinden aşağıdaki formata göre konfigürasyonda verilen paramtreler gönderilir.
parametre1="ip1" parametre2="name" agent="dummyfence"
Haızrladığımız script gönderilen bu bilgiden ip1 ve name parametreleri ayıklanacak şekilde yazılmıştır. Örneğimizde parametre1 node'umuzun servis parametre2 de node'umuzun interconnect ip'sidir. Script'te gönderilen bütün paramtere bloğu stdin'den okunarak parse edilmeye ve device'ların hem interconnect ipleri hemde servis ipleri elde edilmeye çalışılmaktadır. Daha sonra bu bilgilerden faydalanarak hata veren node'u iki thread çalıştırarak reboot etmeyi denyecektir. Biraz ilkel gibi görünsede fence mekanizmasının nasıl çalıştığının alnlaşılması açısından önemli bir örnektir. Yukarıdaki fence ajanına göre bizim konfigürasyon dosyamız aşağıdaki gibi olmalıdır.

Fence işlemini de açıkladıktan sonra cluster mimarisindeki temel bir sorundan bahsetmek istiyorum. Özellikle iki node'lu cluster modellerinde interconnect bağlantıların öneminden daha öncede bahsetmiştik. Açıklamaya çalıştığımız sorun da interconnect ile ilgili ve şu şekilde oluşuyor. Herhangi bir sebeple cluster interconnect'indeki veri haberleşmesi sağlanamazsa ne olur? (Örneğin kullandıkları VLAN taglerinin karışması gibi). Buraya kadar anlattıklarımızdan yola çıkarsak şunu söyleyebiliriz. Kendi konfigürasyonumuza göre 33 sn boyunca TOKEN paylaşımı olmayacağı için her iki node'da diğerinin devre dışı kaldığını zannedecek ve birbirlerini fence etmeye çalışacaklardır. Yani cluster node'ları birbirlerini aynı anda reboot etmeye çalışacaklardır. Bu gibi hangi cluster node'unun gerçekten ayakta olup olmadığının anlaşılmaması durumuna "split brain" adı verilir. Split brain iki node'lu cluster'lar için aşılması güç bir durumdur. Hatta ortak disk kullanımı imkanı olmayan sunucularla oluşturulmuş modellerde bundan kurtulmanın tek yolu konfigürasyona üçüncü bir node eklemektir. Biz kendi kofigürasyonumuzdan gidersek split brain'den kaçınmanın başka bir yolunu kullanabiliriz. Bu da quorum disk kullanmaktır. (Bazı yerlerde tie break olarak da geçebilir.).
Quorum disk temel olarak her iki cluster node'u için disk üzerinden haberleşme sağlamak amacıyla oluşturulmuş bir mekanizmadır. Cluster node'ları birbirleriye hem interconnect üzerinden hemde ortak disk paylaşımı üzerinden haberleşerek cluster'ın durumu hakkında bilgi edinebilirler. (Daha çok eski sürmler için bu durum geçerliydi ancak yeni sürümlerle beraber bu mekanizma değişti. Bu mekanizma artık node'ların network servisinin yanında disk servisininde kontrol edilmesi için kullanılıyor. Biz yine de açıklamaya çalışalım.)
Quorum disk kullanımı için cluster node'ların herhangi birinden quorum için oluşturulmuş (Bizim örneğimizde 1 GB'lık disk) diski aşağıdaki komut ile uygun formata çevirebiliriz.
mkqdisk -c /dev/sdb -l clustertest


Burada quorum altındaki paramatreleri açıklamamız gerekir. Öncelikle "interval" parametresi quorum diskine kaç saniyede bir kontrol verisinin yazılacağını belirler. "device" paramteresi her iki node'dan erişilebilen diskin udev ismidir. tko (technical knock-out) parametresi kaç "interval"den sonra node'un devre dışı sayılacağını belirtir. Buna göre toplma 6 sn boyunca quorum diskine erişemeyen node devre dışı sayılacaktır. "votes" quorum disk erişiminin quorum sayısındaki ağırlığını gösterir.Bu konfigürasyon üzerinden konuşursak cluster yapısında hem online görününen hemde quorum diske yazabilen node iki oy hakkına sahiptir. İki node'lu cluster yapılarında eğer quorum disk kullanılıyorsa qourum sayısını belirleyen konfigürasyon parametreleri aşağıdaki şekilde değiştirilmelidir.
<cman cluster_id="1122" expected_votes="3" port="6809" two_node="0" >
Ancak bu konfigürasyon da split-brain durumunu çözmez. Çünkü her iki node da hem diske erişip hemde kendini online görüyor olabilir. Bunu çözmek için de başka bir parametre devreye girer. Bu parametre "master_wins" dir. Quorum disk mekanizmasında diske erişimi olan bütün node'lardan yalnızca 1 tanesi master olarak seçilir. Eğer master_wins paramteresi =1 yapılırsa quorum diskine erişimi olan node'lardan yalnızca master olarak işaretlenen node, quorum sayısının belirlenmesinde quorum diskinin oy hakkını kullanabilir. Diğer node diske erişebilese bile quorum sayısının belirlenmesinde quorum disk erişimini kullanamaz. Ancak eğer quorum disk master'ı diske erişimini kaybederse diğer node master olarak seçilir ve quorum sayısındaki oy hakkı ona geçer . Bu durumda quorum sayısı sağlanabildiği için cluster hizmet vermeye devam edebilir. Doğru olan konfigürasyon aşağıdaki gibi olmalıdır.

Quorum disk iki node'lu cluster'larda split-brain'den kaçınmak için kullanıldığı gibi bazen de cluster'ın durumunun kesinlik kazandıırlması amacıyla kullanılabilir. Yani node üzerinde network servisleri çalışabiliyorken aynı node SAN üzerinde sorun yaşıyor olabilir. Bu durumda node quorum disk erişimini kaybedeceğinde offline konumuna düşer ve diğer node'lar tarafından fail-over prosedürü başlatılabilir. Cluster mimarinizin düzgün çalışması açısından her durumda quorum disk kullanmakta fayda vardır.
Son olarak quorum ile ccsd servislerinin birbirleri ile ilişkili çalışması için aşağıdaki parametreyi konfigürasyonumuza eklemeliyiz. Bu parametre sayesinde cluster servisi uorum servisini her 33 sn. bir kontrol edecektir.

Buraya kadar cluseter servisleri için gerekli tüm konfigürasyonu tamamlamış olduk. Bundan sonra cluster üzerinden verilecek servisler için bazı düzenlemeler yapacağız. Ama önce cluster'ımız düzgün çalışıyor mu kontrol edelim.
Cluster'ımızı başlatmak için her iki node da aşağıdaki komutları yazmamız gerekir.
temel cluster servisleri için : service cman start
quorum disk servisi için : service qdiskd start


Bu seviyede aşağıdaki komut ile cluster durumunu gözlemleyebilirsiniz.


Yukarıda görüldüğü üzere yalnızca quorum disk uygulamasında master olan node için quorum disk online görünür. Şimdi ufak bir test yapalım. Cluster node'lardan birtanesinin (özellikle quorum diskte master role olanı) inteconnect network'ünü kapatıp neler oluyor gözlemlemleyelim.

Bunun için sanal makinemizin donanım ayarlarında network bağlantı portunu kapatmalıyız. Tam olarak 33 sn. sonra cluster'ımız yapılan bu değişikliğe tepki verecek ve diğer node'u yazdığımız fence device ile restart etmeyi deneyecektir. İşlem sonunda her iki node'un loglarında aşağıdaki bilgiler yer alacaktır.


Özellikle ikinci node'un loglarında görülen " quorum lost, blocking activity" mesajı split brain'in nasıl engellendiğinin anlaşılması açısından önemlidir.
Bu işlemden sonra ikinci node'umuz yeniden başladıktan sonra network ayarları düzeltilip cluster servisleri yukarıda anlatılan şekilde yeniden başlatılmalıdır.
Buaraya kadar cluster'ımızın çalışması için gerekli mininmum konfigürasyon tamamlanmıştır. Bundan sonra cluster üzerinden verilecek hizmetleri düzenleyeceğiz. Makalenin başlığında da görüldüğü gibi cluster'ımız üzerinde oracle servisinin çalışacak şekilde konfigüre edilecektir. Oracle servisinin çalışması için temel olarak üç kaynağa ihtiyacımız vardır. Bunlardan ilki IP adresidir. cluster üzerinde IP servisinin tanımlanması aşağıdaki gibi yapılabilir.

Burada görüldüğü gibi kullanılacak tüm kaynaklar "resource" tag'inde tanımlanabilir. Kullanacağımız ilk kaynak ip adresi bu şekilde tanımlanır. Verilen IP adresi istemcilerin cluster hizmetlerine ulaşırken kullanacakları ip adresidir. "monitor_link" parametresi ise verien ip adresinin erişilebilir olup olmadığının cluster tarafından takip edileceği belirtilir. Burada ip adresine erişimde herhangi bir sıkıntı olması durumunda (örneğin network interface'i için unplugged durumu) cluster otomatik olarak fail-over durumunu başlatacaktır. Ancak diğer fail-over durumundan faklı olarak aktif node üzerindeki servisleri kontrollü olarak diğer node'a geçireceği için herhangi bir fence işlemine gerek duyulmayacaktır. Cluster'da kaynak olarak IP adresi tanımlandıktan sonra servis tanımlama işlemi aşağıdaki gibi gerçekleştirilir.

Tanımlama yapıldıktan sonra (ve her cluster.conf dosyası değişikliğinde) diğer node ile konfiügrasyon eşitlemesi yapılmaldır. Bunun için aşağıdaki komuttan faydalanılabilir.
scp cluster.conf 10.1.28.61:/etc/cluster
Konfigürasyon eşitlendikten sonra cluster servisleri yeniden
başlatılmalıdır. Cluster başlatıldıktan sonra verilecek hizmetlerden sorumlu
olan rgmanager servisi çalıştırılmaılıdır. Bu servis cluster.conf dosyasında
"rm" tag'inde yer alan hizmetlerin yürütülmesinden sorumludur ve
aşağıdaki konut ile başlatılabilir.
service rgmanager start


Görüleceği üzere servisimiz node1 üzerinde aktif durumda çalışmaktadır. Verdiğimiz IP hizmetinin çalışıp çalışmadığını kontrol etmek için basit olarak ping paketleri gönderebiliriz.

Bu aşamadan sonra yine küçük bir test yapalım ve ping servisinin çalıştığı sunucuyu konrolsüz bir şekilde power off edelim. (Yani sunucunun elektriğini keselim) ve cluster'ın davranışını gözlemleyelim.



Yukarıdaki ekran çıktıları incelendiğinde önce kapatılan node'un cluster içersinde offline'a düştüğünü, 33 sn sonra diğer node'un servisi kendi üzerinde çalıştırmaya başladığını görüyoruz. Geçen bu süre ip servisinin hizmet veremediğini ve ikinci node'da servis çalışmaya başladıktan sonra ping paketleri için cevap alabildiğimizi görmekteyiz.
Cluster’ımıza tanımlayacağımız ikinci hizmet ise Oracle instance’ının çalışacağı file system’dir. Bu file system için makalenin başında belirtilen şekilde ortak bir disk alanı ataması yapılmalıdır. Lvm konularına girmemek için şimdilik basit bir şekilde ortak diskimize fdisk yardımıyla partition oluşturup mkfs.ext3 komutu ile file system yapısını oluşturuyoruz. Bu alan yine makalenin başında belirtildiği gibi Oralce Enterprise sürümü için en az 5 GB olmalıdır (> 4,6 GB)
Oluştuduğumuz bu file system’i resource manager tag’inde aşağıdaki parametreler ile tanımlamamız gerekiyor.

Burada verien parametrelerin en önemlileri “device” ve “mountpoint” dir. Bu iki parametreyi kendi sistemimize uygun olacak şekilde düzenledikten sonra service tag’inde aşağıdaki düzenlemeleri yapmalıyız.

Bu iki değişikliği de yaptıktan sonra cluster.conf dosylarını her iki node’da da eşitlemeliyiz. Ve sonrasında herşeyin çalıştığından emin olmak için cluster servislerini yeniden başlatıp küçük bir test yapabiliriz. Eğer cluster servislerini yeniden başlatmak istemiyorsanız cluster.conf dosyasında yer alan “<cluster name="testcluster" config_version="1">” satırındaki “config_version” parametresinin değerini nteger olarak bir artırdıktan sonra dosyayı kaydedip diğer node ‘la eşitledikten sonra aşağıdaki komut yardımıyla konfigürasyon güncellemesi yapabilirsiniz.
ccs_tool update cluster.conf

Eğer herhangi bir sebeple çalışan servislerin diğer node üzernden hizmet vermesini istiyorsak aşağıdaki komutu kullanabiliriz.
clusvcadm –r oracletest –e 10.1.28.60
clusvcadm –e oracletest
Eğer çalışan servisi durdurmak istiyorsak aşağıdaki komutu kullanabiliriz.
clusvcadm –s oracletest
http://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.html
İndirme işlemi tamamlandıktan sonra aşağıdaki linkte verilen işlem adımlarına uygun olarak Oracle kurulumlarını gerçekleştirebilirsiniz.
http://www.oracle.com/webfolder/technetwork/tutorials/obe/db/11g/r1/prod/install/dbinst/dbinst.htm
Kurulum işelmeri tamamlandıktan sonra Oracle ile Cluster yazılımının birlikte çalıştırılması işlemlerini gerçekleştireceğiz. Bunun için Cluster suit yazılımıyla beraber gelen hazır template’ler kullanılabiliriz. Ancak biz bu makalede mimariyi anlatmaya çalıştığımız için hazır template kullanmak yerine kendi scriptimizi yazacağız. Bu script temel olarak Oracle DB sini başlatacak, sonlandıracak ve durumunu kontrol edecektir.
Resource Manager tarafından kullanılacak her script tipindeki kaynağın LSB uyumlu yazılması gerekmektedir. Başka bir deyişle hazırlayacağımız script temel olarak”start”, “stop”, “status”, “monitor” parametrelerine cevap verebiliyor olması gerekir. Bunun için ilk olarak Oracle başlatma scriptimizi aşağıdaki gibi hazırlamalıyız.

Scripti genel olarak incelendiğmizde son derece basit yapılandırılmış olduğunu görebiliriz. Burada il olarak standart oracle shell değişkenlerinin tanılanmasından sonra oracle’a startup komutunu gönderip daha sonra Enterprise Manager (dbconsole) ve Listener’ı (lsnrctl) çalıştırıyoruz.
Hazırlamamız gereken ikinci script ise Oracle durdurma scriptidir. Bu script’de aşağıdaki gibi hazırlanabilir.

Bu scripte yukardıkaine benzer olarak basitçe database’e shudown komutu göndermektedir.
Hazırlamamız gereken üçüncü script ise status için kullanılacaktır. Status Cluster Suit yazılımı tarafından belirli periyotlarda çalışan uygulamanın durumunu konrol etmek için kullanılır. Bu scriptin sonucuna göre uygulamanın çalışıp çalışmadığına karar veren Cluster yazılımı sonuca göre fail-over işlemini gerçekleştirir. Bizim hazırladığımız script temel olarak Oracle üzerinde kopmlex olmayan bir sorgu çalıştırıp sonuç aldığında geriye “0” değeri, sonuç alamadığı zaman da geriye “1” değeri göndererek Cluster yazılımına uygulamanın durumu hakkında bilgi vermektedir. Script aşağıdaki şekilde yazılabilir.

Burada script basit olarak execsql.sql isimli sql script dosyasını veritabaı üzerinde çalıştırır. Execsql.sql sql script dosyası aşağıdaki gibidir.
Bu scriptleri tamamladıktaon sonra sıra Cluster yazılımı tarafından kullanılacak asıl scripte geldi. Bu scriptide yukarıda belirttiğimiz gibi bazı temel parametrelere cevap verebilmek için hazırladığımız alt scriptleri çalıştıracak bir çatı scriptidir.
Bu scriptide hazıladıktan sonra son olarak cluster konfigürasyonumuza eklememiz gerekiyor. Burada göz önünde bulundurulması gereken nokta Cluster yazılımının bu scripti çalıtırmadan önce file system resource’unu mount etmiş olması gerektiğidir. Eğer file system mount edilmeden bu script çalıştırılırsa zaten başarız olacaktır. Bu gibi durumlarda Cluster içindeki servislerin birbiri ile bağımlılıklarını belirtmek için service tree yapısından faydalanılır. Service tree altındaki bir servis bir önceki segmentte bulunan servis başlatılmadan başlatılmaz. Bu yapıyı cluster.conf dosyasında aşağıdaki şekilde tanımlayabiliriz.#!/bin/bash###Oracle Baslatma ve durdurma scripti LSB uyumluRETVAL=0start(){/bin/su - oracle /home/oracle/startupdb.sh >> /tmp/oraclesh.log 2>&1if [[ $? -ge 2 ]];then# Oracle baslatma sirasinda hata olustuRETVAL=1fi}stop(){/bin/su - oracle /home/oracle/shutdowndb.sh >> /tmp/oraclesh.log 2>&1if [[ $? -ge 2 ]];then# Oracle sonlandirma sirasinda hata olustuRETVAL=1fi}status(){RESULT=$(sql | grep '\--' | wc -l)if [[ $RESULT -gt 0 ]];thenRETVAL=0echo "Oracle calisiyor." >> /tmp/oraclesh.log 2>&1elseRETVAL=1echo "Oracle calismiyor." >> /tmp/oraclesh.log 2>&1fi}monitor(){RETVAL=0}case "$1" instart)start;;stop)stop;;status)status;;monitor)monitor;;*)echo $"Usage: $0 {start|stop|status}"exit 2esacexit $RETVAL

Oracle çalışmadan IP servisinin başlatılmasının anlamı olmayacağı için ip resource’uda bu service tree’ye eklenmiştir.
Tüm bu konfigürasyonlar tamamlandıktan sonra cluster.conf eşitlemesiyle beraber her iki node için de /home/oracle klasörlerininde eşitlenmesi gerekiyor.
Bütün bu düzenlemelerden sonra cluster’ımız hazır görünüyor. Sıra geldi bu yapıyı test etmeye. Tüm cluster configürasyonlarını update ettikten sonra servisleri enable edip clustat ile cluster’ımızın durumunu kontrol ediyoruz.

Burada oracle kullanıcısı ile sqlplus çalıştırıp basit bir sorguyla sistemimizi test edebiliriz.

Şimdi servisin çalıştığı ilk node’u kontrolsüz olarak kapatalım ve sonuçları izleyelim.



İlk node’da yaptığımız testi ikinci node’da da gerçekleştirerek Oracle’ımızın sorunsuz çalıştığını görebiliriz.
Makale genelinde genel mimari ve çalışma presipleri üzerinde duruduğumdan clvm gibi daha ayrıntılı konulara pek girmedim. Cluster’ın tam anlamıyla sağlıklı çalışması için bazı ayrıntılar üzerinde de durmak gerekiyor ancak konuyu fazla uzatmamak adına bu çalışmayı burada sonlandırmayı tercih ediyorum. Umarım buradaki bilgiler işinize yarayacak türdendir. Başka bir makalede görüşmek üzere...
Mükemmel bir anlatım. Fence ile ilgili ayrıntılı bilgi arıyordum. Proxmox sanallaştırmada bir türlü aktife edemediğim sistemi sayenizde hayata geçirdim. Sormak istediğim tek birşey var oda quorum olmadan sadece ip adresinden check etmek için cman içeriğine ne yazmamız gerekiyor?
YanıtlaSilŞimdiden Çok teşekkürler.
Selam; Eğer 2 node'lu cluster kuracaksanız
YanıtlaSilile çalıştırabilirsiniz. burada quorum servisini start etmezseniz sorun olmaz. Ancak bu durumda split brain kaçınılmaz olacaktır. Buna dikkat edin.
Bu yorum yazar tarafından silindi.
YanıtlaSilcman cluster_id="1122" expected_votes="2" port="6809" two_node="0"
YanıtlaSil(ilk post da XSS koruması yüzünden silinmiş :) )
Cevabınız için teşekkür ederim. Benim 3 tane nodum var ona göre dizayn etmek istiyorum. 2 nodlu anlatımınızı gördüm fakat benimki 3 nodlu. Fence konusunu sayenizde ne işe yaradığını anladım. Ama projemde 3 nodlu cihaz için nasıl bir fence yazmam gerektiği konusunda şuan kafamda yalnızca ip servisi ile check etmek geliyor. 3 node için önerebileceğiniz bir yöntem varsa çok sevinirim.
YanıtlaSilÜstad mevcut yapım aşağıdaki gibi.
YanıtlaSil?xml version="1.0"?>
Konu ile ilgili yardımlarınızı rica ediyorum mail atabilirseniz sevinirim. umityavz@gmail.com
YanıtlaSilteşekkürler.
Hayırlı günler hocam konu ile ilgili bilgi verebilecekmisiniz ? Şimdiden teşekkürler.
YanıtlaSilBir konu ancak bu kadar mukemmel anlatila bilinir, elinize saglik !
YanıtlaSilHocam, çok güzel olmuş. Teşekkürler ederim.
YanıtlaSilSormak istediğim soru çok temel kaçabilir mantıken idrak edebilmem için işime yarayacak.
Active/passive redhat cluster suit yapısında, tek destek servis kesintisi mi? Disk ile ilgili kısmı nasıldır. Ortak disk alanı olmalı mıdır? İşin içine disk girdiğinde servisler ile olan alakayı kuramıyorum, genellikle drbd ile olan çözümleri görüyorum. Bu yüzden cluster servislerinin çalışma şeklini anlasam da disk tarafında neyı kullanılyorlar, kendi disklerini de mi sürekli sync ediyorlar kafam bayağı karışıyor :)
Merhaba. Bu makaleyi yazali uzun zaman oldu o yuzden tam olarak neyin eksik oldugunu anlayamamakla beraber malesef sorunuzu tam kavrayamadim. Bahsettiginiz sey iki sunucunun ayni anda tek bir dosya sistemi uzerinde islemler gercekletirmesi ise ; kullanacaginiz dosya sistemi uygulamasina gore aktif pasif cluster gerekli olmayabilir. Ornegin oracle ocfs2 ibm gpfs yada symantec veritas gibi. Ancak gfs kullanacaksaniz cluster servisinin calismasi zorunlu. Sorunuzun tam cevabi bu mudur bilmiyorum umarim uardimci olur
Sil